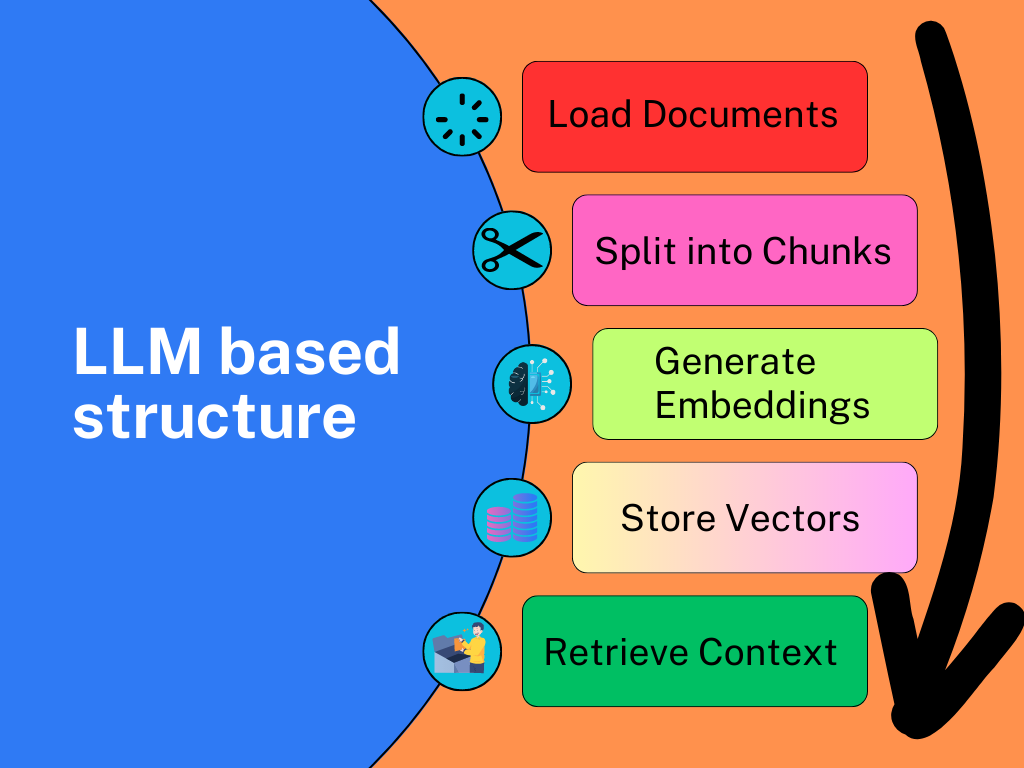
The ultimate LangChain series — Projects structure
Learn how the basic structure of a LangChain project looks

Hey there! I'm Davide, a passionate developer advocate at Chainstack, the leading suite of blockchain infrastructure services.
I'm dedicated to empowering current and aspiring web3 developers by sharing valuable content and resources.
Within my articles, you'll discover a treasure trove of straightforward projects designed to bolster your understanding of fundamental Python, Solidity, JavaScript, and web3 skills. Whether you're a seasoned developer or just starting out, these projects offer an ideal learning path for honing your abilities in the exciting world of blockchain development.
Feel free to explore my articles, and let's embark on this remarkable journey of mastering web3 together!